Pytorch Hyperparameter Tuning Technique
In the last topic, we trained our Lenet model and CIFAR dataset. We found that our LeNet model makes a correct prediction for most of the images as well as we also found overfitting in the accuracy. While our model was not very well trained, it was still able to predict a majority of the validation images.
The CIFAR dataset is going to be more difficult to classify due to the added depth variety and inherent complexity of the training images.
Our very same LeNet model which performed very well with the MNIST datasets is now having issues in classifying our CIFAR dataset accurately.
There are two main issues from which we are currently dealing with. The accuracy not being high enough, and the network seems to be overfitting our training data. The first issue can be tackled using a variety of modification to our LeNet model code. The modification which we will apply are very case dependent and fine-tuning of our model capacity. It is often a very specific process which is unique for each specific deep learning task.
However, the fine-tuning of our model is important and can improve our model performance significantly. We must always try and modify our model to see just how these modifications improve the effectiveness of our model. We will apply the following modification:
1) The first modification will be focused on the learning rate. The Adam optimizer computes individual adaptive learning rates. It is still important to specify a fitting learning rate for optimal performance. A learning rate that is too high can often lead to lower accuracy. A lower learning rate can help a neural network to learn more effectively when a more complex dataset is involved.
Note: A learning rate which is too small can significantly slow down our training performance.
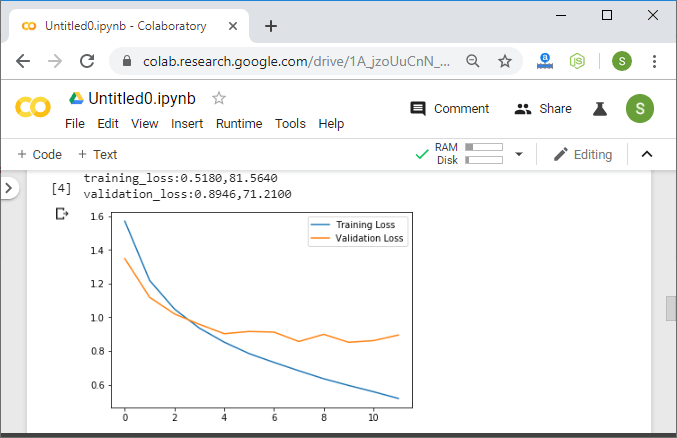
With the help of both analytical and empirical, we conclude that the training process is quite slow, and the training and validation accuracies are not significantly improved from one epoch to the next.
We will set the learning rate from 0.001 rather than 0.0001.


2) The second modification is very effective. We will simply add more convolution of layers. By adding more convolution, our network can extract features more effectively and also lead to improving accuracy.
Note: A common architecture of defining a convolution layer is one where each layer doubles the depth of the output of the preceding layer.
In our first convolutional layer, there will be 3 input channel and the depth of conv1 corresponding to 16 output channel. This is then going to be double to 32 and then 64 as:
When we proceeded from one convolution layer to the next,- the depth of the output of the convolution layer had increased consistently. By doing so, we internally increased the number of filters to extract highly sophisticated information related to the forward an input. Convolution layers are used to make the network much deeper that extract more and more complex features.
So we will make another convolutional layer conv3 as:
The appropriate vector which is being fed into our fully connected layer will be five by five, which is same as before, but the number of output channel will be 64.
To ensure consistency, we will also change the number of output channels in our forward’s view method as:
After initializing third convolutional layer, we will apply relu function on it as:
A larger kernel implies more parameters. We will use a smaller kernel size to remove overfitting. We will use a kernel size of three, which will be suitable for our code. Previously in the MNIST dataset, we did not use any padding in our convolutional layer, but now we are dealing with a more complex dataset. It would make sense to preserve the edge pixels of our image by including padding to ensure maximal feature extraction. We will set padding to 1 for all convolutional layer as:
The final vector which is fed into the fully connected layer is dictated by the image size that will half at every max-pooling layer. The image size will be reduced as:

So we will change our nn.Linear method of initializer as:
Similarly, we will change the forward’s view method as:
Now, we will train it, and it will give us the following expected output: